地质文献和矿产勘查报告是地质信息的重要来源,对于了解地质过程、促进矿产勘查至关重要。然而,如何从海量的地质文本数据中提取有价值的信息,一直是地质领域面临的挑战。近年来,人工智能和自然语言处理技术的飞速发展为解决这一难题提供了新的途径。中国科学院新疆生态与地理研究所新疆矿产资源研究中心科研人员在这方面取得了重要进展,提出了一种基于多特征融合的锂矿命名实体识别方法,以支持锂矿AI找矿预测和勘探工作。
该研究通过引入多头注意力机制,将地质实体类型信息融入文本特征表示,从而提升了锂矿命名实体识别的准确性。研究团队创新性地利用了21种锂矿实体类型,结合CNN和Bi-LSTM模型,综合了字特征、词特征和上下文特征,提高了模型的识别效果。此外,研究还通过引入边界预测任务,针对地质实体的头尾特征进行了增强,提升了模型对地质实体边界的识别能力。
这种方法不仅能够准确识别地质文本中的锂矿相关实体,还能为地质领域的其他文本挖掘任务提供有力支持。研究成果为基于AI进行锂矿找矿和勘探工作提供了重要的技术支持,同时为地质文本的自动化分析、知识发现及应用推广提供了新的方向。
研究成果以“Multi-feature Fusion-based Lithium Deposit Named Entity Recognition for Geoscience Texts”为题发表在《Ore Geology Reviews》。研究由中国科学院新疆生态与地理研究所作为第一单位,2021级博士生陶金涛为第一作者,新疆矿产资源研究中心张楠楠研究员为通讯作者。该研究得到新疆科技创新领军人才项目、自治区重大专项等项目的支持。
文章链接: https://doi.org/10.1016/j.oregeorev.2024.106367
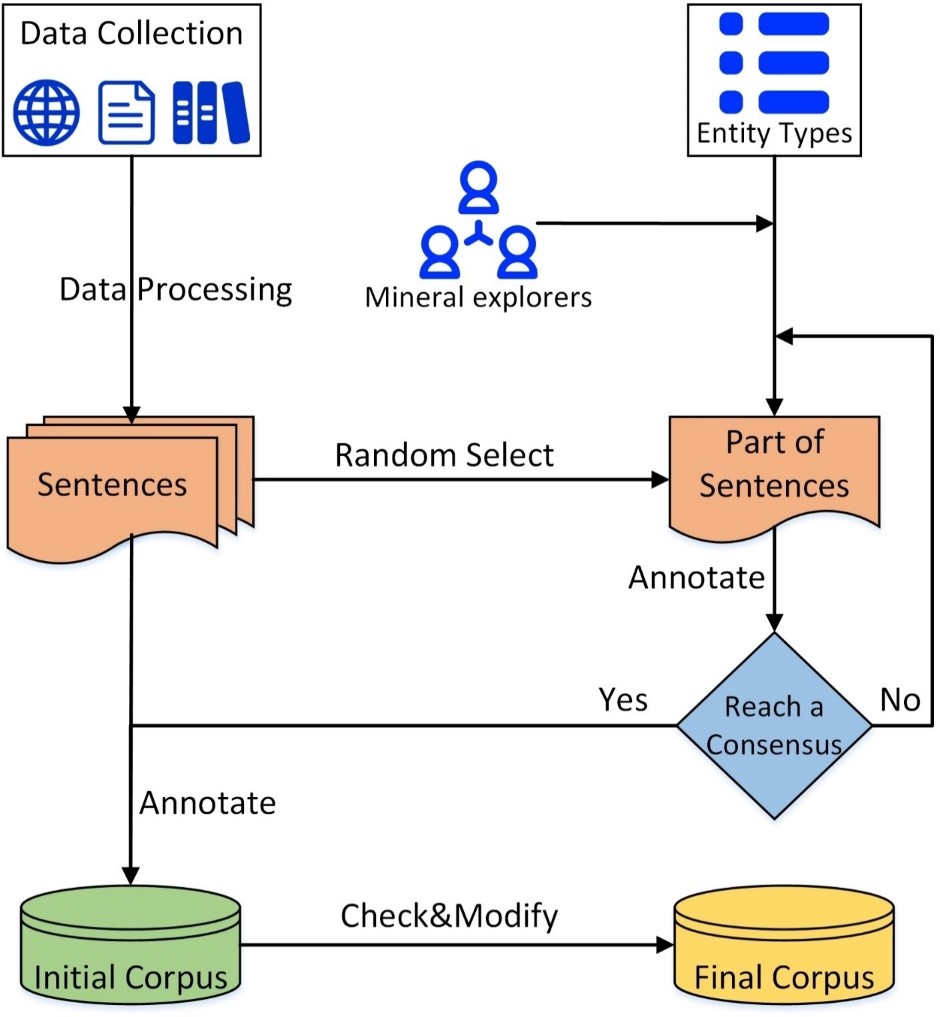
图1: 语料库构建流程
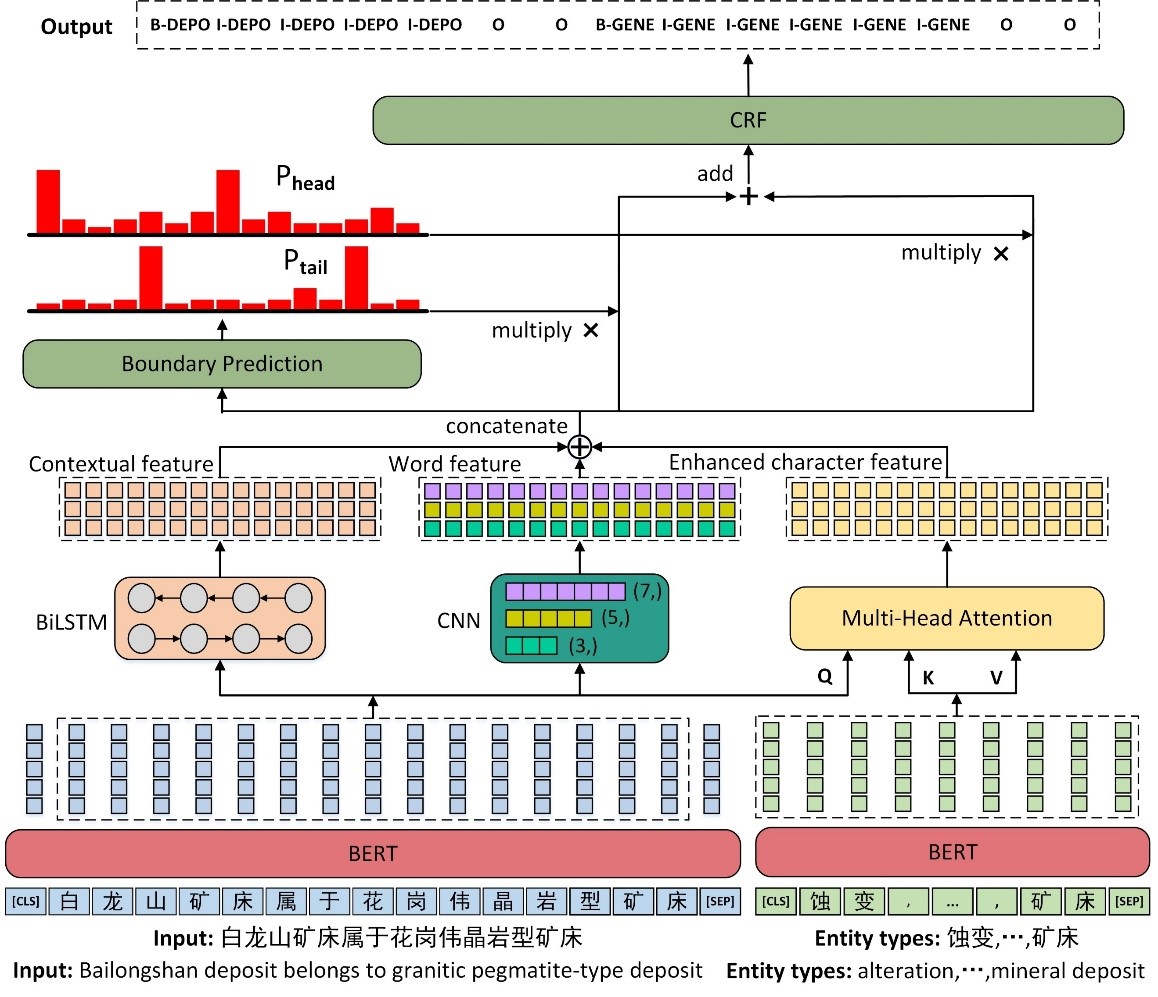
图2:模型结构

图3:不同实体类型的词云:(a) 岩浆岩,(b)矿物,(c)空间位置 和(d)变质岩。所有英文词汇均表示其对应的中文词汇
 附件下载:
附件下载: 微信公众号
微信公众号